35편. 스트림(Streams) (1)

들어가기 앞서
자바로 작성된 수많은 프로그램들의 내부에서는 갖가지의 컬렉션(collection)을 만들고 이를 이용해 데이터를 처리합니다. 예를 들어서, 우리는 매장 내 물품의 재고량이나 가격, 제조일자, 브랜드 등을 나타내는 물품의 컬렉션을 만들 수 있습니다. 그리고 이 컬렉션을 이용하여 재고가 없는 물품을 검색하거나 가격이 낮은 순으로 정렬시키는 등 다양한 작업을 수행할 수 있습니다.
public static void main(String[] args) { List<Product> products = productService.getProducts(); products.add(new Product(1, "External Hard Drive",59990, 15)); products.add(new Product(2, "Laptop Backpack", 30000, 18)); products.add(new Product(3, "Camera Lens Protector", 8000, 11)); // ... List<Product> filteredProductsByPrice = new ArrayList<>(); for (Product product : products) { if (product.getPrice() <= 30000) { filteredProductsByPrice.add(product); } } filteredProductsByPrice.sort(new Comparator<Product>() { @Override public int compare(Product o1, Product o2) { return Integer.compare(o1.getPrice(), o2.getPrice()); } }); List<String> filteredProductNames = new ArrayList<>(); for (Product filteredProduct : filteredProductsByPrice) { filteredProductNames.add(filteredProduct.getName()); } // ... }
우리는 이런 데이터를 다루면서 반복적으로 특정 조건에 부합하는 데이터들을 검색하거나, 어떤 기준에 따라서 그룹화하거나, 정렬하거나, 최댓값 혹은 최솟값 아니면 총합을 찾는 등의 작업을 처리할 필요가 있습니다. 만약에 여러분이 데이터베이스의 질의문을 알고 있다면, 개발자가 해당 기능의 구현을 생각할 필요 없이 "SELECT id, name, price FROM products WHERE price <= 30000 ORDER BY price"와 같이 얻고 싶은 결과가 무엇인지 나타낼 수 있습니다. 다시 말하면, 개발자는 어떻게 해야 하는지 지시하지 않고 무엇을 해야 하는지 지시하는 것입니다. 그러면 컬렉션도 마찬가지 방식으로 처리할 수 없을까요? 자바 8에서는 스트림 API를 통해서 위의 코드를 SQL처럼 간단하게 작성할 수 있습니다(C#의 LINQ와 비슷합니다).
public static void main(String[] args) { // ... List<String> filteredProductNames = products.stream() .filter(p -> p.getPrice() <= 30000) .sorted(Comparator.comparing(Product::getPrice)) .map(Product::getName) .collect(Collectors.toList()); // ... }
위의 두 코드는 동일한 기능을 수행합니다. 첫 번째 코드와 비교하면 위의 코드는 상당히 간결하고 해당 코드가 어떤 기능을 하는지 보다 쉽게 파악할 수 있습니다. 스트림은 이외에도 강력한 기능들을 지원하지만 이건 차차 알아가보도록 합시다.
스트림(Stream)
스트림(Stream)은 자바 8에서 추가된 기능입니다. 들어가기 앞서, 여기서 말하는 스트림은 입출력(I/O)에서 말하는 스트림과는 전혀 다르므로 주의합시다. 스트림을 간단하게 정의하면 "순차 및 병렬로 이루어지는 집계 연산을 지원하기 위해서 소스에서 추출된 일련의 요소"를 말합니다. 이해하기 쉽도록 각각을 분해해봅시다. 아래는 대략적인 스트림의 흐름을 나타낸 그림입니다.
- 순차 및 병렬: 스트림은 단일 코어를 활용하여 작업을 순차적으로 처리할 수도 있고, 멀티코어 프로세서를 활용하여 작업을 병렬로 손쉽게 처리할 수도 있습니다. 기본적으로 스트림은 순차 스트림이며 개발자가 임의로 병렬 스트림으로 전환시킬 수도 있습니다. 우선은 순차 스트림을 먼저 살펴보고 이어서 병렬 스트림을 살펴보도록 합시다.
- 집계 연산: 집계 연산은 각각의 요소마다 수행하는 연산이 아니라, 자료 구조 전체를 대상으로 수행하는 연산을 말합니다. 예를 들어서, 어떤 데이터들의 총합이나 평균, 최댓값, 최솟값 등을 구하는 연산을 말합니다.
- 소스(source): 말 그대로 데이터 원본을 말합니다. 스트림은 컬렉션, 배열, I/O 자원 등의 데이터 원본에서 데이터를 소비합니다. 여기서 소비한다는 뜻은 데이터 원본을 수정하지 않고 데이터를 꺼내서 쓴다는 의미입니다. 즉, 기존의 컬렉션(데이터 원본)을 통해 스트림을 만들어도 해당 컬렉션에 요소가 추가되거나, 순서가 변경되는 일은 일어나지 않습니다.
- 일련의 요소: 컬렉션과 마찬가지로 순차적으로 값에 접근합니다. 덧붙여서, 스트림은 컬렉션 같이 실제로 요소를 저장하는 자료 구조가 아니며 필요에 따라서 그때그때 계산한다는 사실을 명심해둡시다. 이에 대해서는 다시 한번 살펴볼 것입니다.
그리고 스트림 연산은 아래와 같이 컬렉션 연산과는 크게 다른 기본적인 특징들이 있습니다. 이어서 살펴보도록 합시다.
파이프라이닝(Pipelining)
많은 스트림 연산이 스트림 자체를 반환합니다. 이를 통해서 각 작업을 체인으로 연결하여 더 큰 파이프라인을 만들 수 있습니다. 즉, 메서드의 출력이 다음 메서드의 입력이 되어서 이어서 작업을 처리합니다.
public interface Stream<T> extends BaseStream<T, Stream<T>> { Stream<T> filter(Predicate<? super T> predicate); <R> Stream<R> map(Function<? super T, ? extends R> mapper); Stream<T> distinct(); Stream<T> sorted(); Stream<T> sorted(Comparator<? super T> comparator); Stream<T> peek(Consumer<? super T> action); // ... }
이런 특징을 통해서 지연 평가(lazy evaluation)나 단락 평가(short-circuit evaluation) 등의 최적화를 할 수 있습니다. 이는 잠시 후에 다시 살펴볼 것입니다.
내부 반복(Internal iteration)
자바 7까지는 컬렉션을 다룰 때 개발자가 직접 이터레이터(iterator)를 사용해서 반복을 제어해야 했습니다. 이를 외부 반복(external iteration)이라고 하며, 명시적 반복(explicit iteration)이라고 부르기도 합니다. 예를 들어서 점수가 담겨있는 정수 리스트에서 80점을 넘는 점수에는 어떤 것이 있는지 확인할 때는 아래와 같이 작성해야 했습니다.
List<Integer> scores = Arrays.asList(70, 50, 70, 80, 65, 90, 100); // 이터레이터를 사용하는 방법 for (Iterator<Integer> iter = scores.iterator(); iter.hasNext(); ) { Integer score = iter.next(); if (score >= 80) { System.out.println(score); } } // 개선된 for문을 사용하는 방법(for-each, 내부적으로 이터레이터를 사용함) for (Integer score : scores) { if (score >= 80) { System.out.println(score); } }
반면에 스트림은 내부 반복을 사용합니다. 내부 반복은 개발자 대신에 라이브러리 혹은 프레임워크가 제어하며, 개발자는 그저 수행해야 할 작업을 지시하기만 합니다. 아래의 코드를 실행시키면 위의 코드와 동일한 결과를 얻을 수 있을 것입니다. 외부 반복과 비교하면 내부 반복의 코드가 더 간결하며 가독성이 더 높습니다. 또한, 개발자는 작성해야 하는 코드가 상대적으로 적으며 세부적인 내용은 신경쓰지 않아도 되므로 실수를 할 가능성이 낮아집니다. 물론 내부 반복은 외부 반복에 비해서 세밀한 제어를 할 수 없으므로 유연성이 다소 떨어지는 단점이 있습니다.
scores.stream().filter(score -> score >= 80) .forEach(System.out::println);
물론 내부 반복이라고 해서 컴파일러가 마법을 부리는 것은 아니며 외부 반복과 마찬가지로 내부적으로 이터레이터를 사용합니다. 다만 개발자가 직접 제어하는가 프레임워크/라이브러리가 제어하는가에 차이가 있습니다.
연산 살펴보기
연산의 분류
서로 연결할 수 있는 스트림 연산을 중간 연산(intermediate operation)이라고 합니다. 반환형이 스트림이기 때문에 서로 연결할 수 있습니다.
long femalesMoreThan24y = peopleList.stream() // Stream<Person> 타입의 객체를 반환하는 중간 연산 .filter(person -> person.getGender().equals(Gender.FEMALE)) // Stream<Integer> 타입의 객체를 반환하는 중간 연산 .map(Person::getAge) // Stream<Integer> 타입의 객체를 반환하는 중간 연산 .filter(age -> age > 24) // 최종 연산. 스트림의 요소 수를 반환한다. .count();
위의 예시에서 count()와 같이 스트림 파이프라인을 닫는 연산을 최종 연산(terminal operation)이라고 합니다. 최종 연산의 반환형은 스트림이 아니며 보통 List, Integer, void 등과 같은 타입의 결과를 반환합니다. count() 메서드의 경우는 long 타입의 값을 반환합니다.

그렇다면 왜 이렇게 스트림 연산을 중간 연산과 최종 연산으로 분류할까요?
지연 평가(lazy evaluation)
중간 연산은 최종 연산이 호출될 때까지 실제 작업은 수행되지 않는다는 점 때문입니다. 위의 예시에서는 count() 메서드가 호출되기 전까지 아무런 작업도 수행하지 않습니다. 즉, 평가를 원하는 시점까지 뒤로 미룹니다. 왜 게으른(lazy) 평가라고 불리는지 짐작이 가시나요? 그러면 이런 특징으로 얻을 수 있는 이익은 무엇일까요?
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8); /** * 1. 정수 리스트에서 짝수만 남기고 홀수는 걸러낸다. (filter()) * 2. 1번에서 구한 짝수들을 각각 제곱한다. (map()) * 3. 결과는 최대 2개로 제한한다. (limit()) * 따라서, 최종 결과는 [4, 16]이 될 것이다. */ List<Integer> twoEvenSquares = numbers.stream() // filter()는 말 그대로 각 요소가 조건에 부합하는지 // 걸러내는 것이다. 조건에 맞는 요소들을 모아 새로운 // 스트림을 생성한다. .filter(n -> { System.out.println("filtering " + n); return n % 2 == 0; }) // 현재 스트림의 각 요소마다 동일한 연산을 거치고 난 뒤에 // 새로운 스트림을 생성한다. .map(n -> { System.out.println("mapping " + n); return n * n; }) // 말 그대로 스트림의 길이를 제한한다. 스트림은 최대 2개의 // 요소를 가질 수 있다. .limit(2) // 이렇게 작업이 모두 끝난 뒤의 스트림의 각 요소를 받아서 // 컬렉션에 저장한다. .collect(Collectors.toList());
위의 코드를 실행해보면 흥미로운 결과를 얻을 수 있습니다. 중간 연산인 filter()와 map()이 하나로 합쳐진 뒤 단일 경로로, 마치 하나의 연산인 것처럼 실행되기 때문입니다. 이를 루프 퓨전(loop fusion)이라고 부릅니다. 이름 그대로 최적화를 통해서 여러 개의 루프가 하나의 루프로 결합되는 것입니다.
filtering 1 filtering 2 mapping 2 filtering 3 filtering 4 mapping 4
단락 평가(short-circuit evaluation)
그리고 또 하나 놀라운 점이 있습니다. numbers 리스트에 있는 8개의 요소를 모두 검사하지 않고 1, 2, 3, 4와 같이 단 4개의 요소만 검사했기 때문입니다. 이는 우리가 limit() 메서드를 통해 최종 스트림의 길이를 2로 제한했으므로 스트림의 길이가 2가 됐을 때 더 이상 중간 연산을 실행할 필요가 없기 때문입니다. 연산자 편에서 이미 설명한 단락 평가(short-circuit evaluation)를 이용한 것입니다. 이런 특징은 무한 스트림(infinite stream)을 만들 때 유용합니다.
// iterate()에는 초기값과 람다식을 넘긴다. 넘긴 람다식은 다음 요소를 생성할 때 사용된다. // 여기서 intStream은 요소가 수없이 많은 무한 스트림이다. 따라서 이를 출력하면 // 1 -> 2 -> 3 -> 4 -> 5 -> ...처럼 1씩 증가하며 끝없이 출력될 것이다. Stream<Integer> intStream = Stream.iterate(1, i -> i + 1); intStream.forEach(System.out::println);
이를 limit() 메서드를 이용하여 최종 스트림의 요소 수를 제한하면 무한 스트림에서 지정한 수만큼 요소를 뽑아올 수 있습니다.
Stream<Integer> intStream = Stream.iterate(1, i -> i + 1); List<Integer> collect = intStream .limit(5) .collect(Collectors.toList()); collect.forEach(System.out::println);
다양한 연산 활용하기 (1)
스트림 생성하기(Creating streams)
먼저 스트림을 만드는 방법에 대해서 알아봅시다. 참고로 스트림을 만드는 방법을 모두 알 필요는 없고 간단하게 보고만 넘어가도 무방합니다.
Stream.of()
아래에서 보는 바와 같이 가변인자를 사용합니다. 이 정적 메서드는 우리가 건네준 값들의 순서를 유지한 채로 새로운 스트림을 생성합니다.
public static<T> Stream<T> of(T... values) { ... }아래와 같이 스트림을 만들 수 있습니다. 2번과 같이 배열을 인수로 넘길 수 있지만, 여기서 new int[]가 아닌 new Integer[]를 써야함에 주의합시다. 제네릭의 타입에는 기본 타입을 적을 수 없으므로 참조 타입을 적어야 합니다. 기본 타입을 쓰고 싶다면 기본 타입에 특화된 IntStream을 사용해야 하는데 이는 나중에 다른 특화 스트림들과 같이 살펴보도록 하겠습니다.
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5); // (1) Stream<Integer> stream = Stream.of(new Integer[] {1, 2, 3, 4, 5}); // (2)
추가로, Stream.of() 메서드는 소스가 널이면 NullPointerException가 발생합니다. 여기서 소스가 널이 될 수 있는 경우에는 자바 9부터 추가된 Stream.ofNullable() 메서드를 사용할 수 있습니다. 이 메서드는 소스가 널이면 빈 스트림(Stream.empty())을 반환합니다.
public static<T> Stream<T> ofNullable(T t) { return t == null ? Stream.empty() : StreamSupport.stream(new Streams.StreamBuilderImpl<>(t), false); }
Arrays.stream()
이 메서드는 배열인 소스로부터 스트림을 생성합니다. 기본 타입인 int, long, double의 배열로부터 스트림을 생성할 수도 있습니다. 기본 타입 특화 스트림을 반환하는 stream() 메서드가 따로 정의되어 있기 때문입니다.
public static <T> Stream<T> stream(T[] array) { ... } public static <T> Stream<T> stream(T[] array, int startInclusive, int endExclusive) { ... }
아래와 같이 스트림을 만들 수 있습니다.
Stream<Integer> stream = Arrays.stream(new Integer[] {1, 2, 3, 4, 5}); IntStream stream = Arrays.stream(new int[] {1, 2, 3, 4, 5});
여기서 startInclusive, endExclusive 파라미터는 배열의 시작 인덱스와 마지막 인덱스를 말합니다. 주의할 점은 시작 인덱스는 포함(inclusive)되고, 마지막 인덱스는 제외(exclusive)된다는 것입니다.
// 여기서 인덱스 2부터 인덱스 3까지의 요소를 가져와 스트림을 만드므로 3과 4가 출력된다. // 인덱스 4(endExclusive)는 범위에서 제외된다는 점을 주의하자. Arrays.stream(new Integer[] {1, 2, 3, 4, 5}, 2, 4) .forEach(System.out::println);
Collection.stream()
이 메서드는 컬렉션인 소스로부터 스트림을 생성합니다. 아래와 같이 Collection 인터페이스에 디폴트 메서드로 선언되어 있습니다.
public interface Collection<E> extends Iterable<E> { // ... default Stream<E> stream() { ... } }
아래와 같이 스트림을 만들 수 있습니다.
List<Integer> nums = new ArrayList<>(); // ... Stream<Integer> stream = nums.stream();
Stream.generate(), Stream.iterate()
이 두 메서드는 무한 스트림을 만들 때 사용합니다. 여기서 generate()는 값을 소비하지 않고 그저 생산해냅니다. 즉, 입력 없이 어떤 값을 반환하므로 상수 스트림이나 랜덤 요소 스트림 등을 만들 때 사용할 수 있습니다.
public interface Stream<T> extends BaseStream<T, Stream<T>> { // .... // 메서드 선언 public static<T> Stream<T> generate(Supplier<? extends T> s) { ... } } // 실제 사용 Stream<Integer> stream = Stream.generate(() -> new Random().nextInt(10)); // 0 이상 10 미만의 범위에서 무작위로 수를 5개를 출력한다. stream.limit(5).forEach(System.out::println);
iterate()는 이전 값을 가지고 다음 요소를 생성할 때 사용합니다. 우선 처음에는 이전 값이 없으므로 초기값을 같이 넘겨줘야 합니다.
public interface Stream<T> extends BaseStream<T, Stream<T>> { // ... // 메서드 선언 public static<T> Stream<T> iterate(final T seed, final UnaryOperator<T> f) { ... } // 자바 9에서 추가되었으며 두 번째 인수로 술어(조건)를 지정할 수 있다. // 지정한 조건을 만족하지 않는 경우 iterate()가 중단된다. public static<T> Stream<T> iterate(T seed, Predicate<? super T> hasNext, UnaryOperator<T> next) { ... } } // 실제 사용 Stream<Integer> stream = Stream.iterate(1, i -> i + 1); // 초기값인 1부터 시작하여 1, 2, 3, 4, 5가 순서대로 출력될 것이다. stream.limit(5).forEach(System.out::println); stream = Stream.iterate(1, i -> i <= 10, i -> i + 1); // 조건 i <= 10에 맞는 요소들만 출력되므로 1, 2, ..., 9, 10이 순서대로 출력될 것이다. stream.forEach(System.out::println);
Stream.builder()
자주 사용하지는 않지만 아래와 같이 스트림 클래스의 빌더 메서드를 사용해서 스트림을 만들 수도 있습니다. 내부적으로는 요소 삽입에 상당히 최적화되어 있는 자료 구조를 사용합니다.
Stream<Integer> stream = Stream.<Integer>builder() .add(1) .add(2) .add(3) .build(); stream.forEach(System.out::println);
필터링(Filtering)
filter: 원하는 데이터만 가져오기
조건에 부합하지 않는 데이터는 걸러내고, 조건을 충족하는 데이터는 가져오고 싶을 때는 어떻게 해야 할까요? 바로 filter() 메서드를 사용하면 됩니다. 이 메서드에 술어(predicate)를 넘겨서 조건에 맞는 요소들로 구성된 새로운 스트림을 만들 수 있습니다. 직관적으로 메서드의 이름만 보면 주어진 조건이 참이라면 걸러낼 것 같지만 반대라는 사실에 주의합시다.
Stream<T> filter(Predicate<? super T> predicate);아래는 여러 개의 이름 중에 '김'으로 시작하는 이름을 뽑아서 순서대로 출력하는 예제입니다.
List<String> names = Stream.of("홍길동", "홍길순", "김철수", "김영희").stream() .filter(n -> n.startsWith("김")) .collect(Collectors.toList()); names.forEach(System.out::println); // 김철수, 김영
distinct: 중복 제거하기
스트림에서 각 요소를 모두 고유하게 만들고 싶으면, 즉 중복을 제거하고 싶으면 distinct() 메서드를 사용할 수 있습니다. 스트림 내의 두 요소가 서로 동일한지 확인할 때 equals()와 hashCode() 메서드를 사용하므로 올바른 결과를 얻으려면 이 메서드를 오버라이딩해야 합니다.
Stream<T> distinct();순서가 있는 스트림에 distinct()를 사용한 경우에는 처음으로 등장한 요소는 유지되고 그 이후로 중복된 요소들은 제외됩니다. 순서가 없는 스트림에서는 어느 요소가 남고 제외되는지 알 수 없습니다.
Stream.of(1, 2, 2, 3, 3, 4, 4, 5) .filter(i -> i % 2 == 0) .distinct() .forEach(System.out::println); // 2, 4
검색과 매칭(Finding and matching)
anyMatch: 조건에 맞는 데이터가 하나라도 있는지 검사하기
인수로는 술어(predicate)를 넘기며, 스트림 내에 주어진 조건에 맞는 요소가 하나라도 있으면 true를 반환합니다. 아래에서 보는 바와 같이 반환형이 boolean인 최종 연산입니다.
// 빈 스트림인 경우에는 조건에 맞는 요소가 하나도 없는 것과 동일하므로 false를 반환한다. boolean anyMatch(Predicate<? super T> predicate);
예를 들어서 0보다 큰 수가 하나라도 있는지 검사하기 위해선 아래와 같이 코드를 작성할 수 있습니다. 0보다 큰 수인 2와 4가 있으므로 결과는 true가 됩니다.
boolean isAnyGreaterThanZero = Stream.of(-4, -2, 0, 2, 4) .anyMatch(i -> i > 0); System.out.println(isAnyGreaterThanZero); // true
allMatch: 데이터가 모두 조건을 만족하는지 검사하기
인수로는 술어(predicate)를 넘기며, 스트림 내의 모든 요소가 주어진 조건을 만족한다면 true를 반환합니다. 아래에서 보는 바와 같이 반환형이 boolean인 최종 연산입니다.
// 직관에 반할 수도 있지만 빈 스트림인 경우에는 true를 반환한다. 조건에 부합하지 않는 요소를 예로 들 수 없기 때문이다. boolean allMatch(Predicate<? super T> predicate);
예를 들어서 모든 요소가 짝수인지 검사하기 위해선 아래와 같이 코드를 작성할 수 있습니다.
boolean isAllEven = Stream.of(2, 1024, 2048, 512, 4096) .allMatch(i -> i % 2 == 0); System.out.println(isAllEven); // true
noneMatch: 조건을 만족하는 데이터가 하나도 없는지 검사하기
인수로는 술어(predicate)를 넘기며, 스트림 내에 주어진 조건을 만족하는 요소가 하나도 없다면 true를 반환합니다. 아래에서 보는 바와 같이 반환형이 boolean인 최종 연산입니다.
// 직관에 반할 수도 있지만 allMatch와 마찬가지로 빈 스트림인 경우에는 true를 반환한다. 조건에 부합하는 요소를 예로 들 수 없기 때문이다. boolean noneMatch(Predicate<? super T> predicate);
예를 들어서 짝수인 요소가 하나도 없는지 검사하기 위해선 아래와 같이 코드를 작성할 수 있습니다.
boolean isNoneEven = Stream.of(1, 3, 5, 7, 9) .noneMatch(i -> i % 2 == 0); System.out.println(isNoneEven); // true
findAny: 현재 스트림에서 임의의 요소 반환하기
어떤 요소인지는 관심 없고 그저 요소가 존재하기만 하면 상관없을 때 사용할 수 있습니다. 아래에서 보는 바와 같이 반환형이 Optional<T>인 최종 연산입니다. 주의할 점은 순서가 있는 스트림에서는 처음 요소를 가져오지만, 순서가 없는 스트림에서는 정확히 어떤 요소를 가져올 것인지는 장담할 수 없습니다. 같은 결과를 가져오는 것 같아도 항상 똑같은 결과를 가져올지는 알 수 없습니다. 다시 말해서, 말 그대로 '임의의' 요소를 반환합니다.
// 빈 스트림인 경우 빈 Optional을 반환한다. Optional<T> findAny();
위에서 잠시 살펴본 limit()과 마찬가지로 임의의 요소를 발견하면 그 이후에는 더 이상 중간 연산을 실행할 필요가 없으므로 거기서 끝이 납니다. 아래 예시를 돌려보면 보다 쉽게 이해할 수 있을 것입니다.
Optional<Integer> num = Stream.of(1, 3, 2, 7, 8, 6) .filter(n -> { System.out.println("filtering " + n); return n % 2 == 0; }) .findAny(); num.ifPresent(System.out::println); // 2 (보장되지 않음)
findFirst: 현재 스트림에서 처음 요소 반환하기
아래에서 보는 바와 같이 반환형이 Optional<T>인 최종 연산입니다. 순서가 있는 스트림에서는 처음 요소를 반환하지만, 순서가 없는 스트림에서는 어떤 요소든 반환될 수 있습니다.
// 빈 스트림인 경우 빈 Optional을 반환한다. Optional<T> findFirst();
아래의 예를 보면 배열은 순서가 있는 자료구조이므로 조건에 맞는 요소들 중 처음 요소인 2가 출력됨을 알 수 있습니다.
Optional<Integer> num = Stream.of(1, 3, 2, 7, 8, 6) .filter(n -> { System.out.println("filtering " + n); return n % 2 == 0; }) .findFirst(); num.ifPresent(System.out::println); // 2 (보장됨)
슬라이싱(Slicing)
말 그대로 스트림을 조각낼 때 사용하는 연산들입니다. 다시 말하면 두 위치 사이에 있는 요소들을 가져오거나, 어느 위치를 기점으로 전후에 있는 요소들을 가져오는 등의 연산을 하고 싶을 때 아래의 연산들을 사용할 수 있습니다.
takeWhile: 현재 스트림에서 조건에 맞는 요소들 가져오기
인수로 술어(predicate)를 넘겨야 합니다. 기능만 보면 얼추 filter()와 비슷한 것 같지만 takeWhile()은 조건에 맞지 않는 요소를 처음 만났을 때 스트림이 닫힌다는 차이가 있습니다. 좀 더 자세히 서술하면 순서가 있는 스트림에선 현재 스트림에서 앞단부터 시작하여 조건을 만족하는 가장 긴 순열을 뽑아온다고 생각하면 됩니다. 순서가 없는 스트림에서는 스트림 내의 요소들 중 조건에 맞는 요소들로 이루어진 부분집합을 반환합니다.
// 자바 9부터 지원한다. // 이 연산은 '상태를 유지하는 단락 중간 연산(short-circuiting stateful intermediate operation)'이다. 따라서 병렬에다가 순서가 있는 스트림인 경우에는 비용이 많이 들 수 있으므로 주의해야 한다. // 순서가 있는 스트림에서 조건에 맞는 어떤 요소를 가져오려고 할 때, 먼저 이전의 요소들이 전부 처리되었는지 확인해야 하기 때문이다. default Stream<T> takeWhile(Predicate<? super T> predicate) { ... }
이해를 돕기 위해서 아래의 예시를 살펴봅시다. 현재 스트림에서 짝수인 요소들만 뽑아서 새로운 스트림을 만들고 싶은데, 막상 결과를 실행해보면 2, 12, 14, 6만 출력되고 8과 10은 출력되지 않습니다. 왜냐하면 처음부터 끝까지 검사를 해나가다가 홀수인 7을 만나서 조건이 거짓이 된 후로 스트림이 닫히기 때문입니다.
Stream.of(2, 12, 14, 6, 7, 8, 10) // Stream<Integer> .takeWhile(i -> i % 2 == 0) .forEach(System.out::println); // 2, 12, 14, 6이 출력된다.
이번에는 순서가 없는 스트림에서는 결과가 어떻게 나오는지 살펴보도록 합시다. 셋(Set)은 순서가 없는 전형적인 자료구조입니다. 아래의 코드를 실행하면 매번 결과가 다르게 나올 것입니다. 심지어는 빈 스트림을 반환할 수도 있습니다. 순서가 정해져 있지 않기 때문에 어느 것부터 먼저 처리하냐에 따라서 결과가 계속 달라지는 것입니다.
Set.of(2, 12, 14, 6, 7, 8, 10).stream() // Stream<Integer> .takeWhile(i -> i % 2 == 0) .forEach(System.out::println); // 조건에 맞는 부분집합이 출력됨
dropWhile: 현재 스트림에서 조건에 맞지 않는 요소들 가져오기
인수로 술어(predicate)를 넘겨야 합니다. dropWhile()은 takeWhile()과 비슷하지만, 조건에 맞는 요소들을 제외(drop)시킵니다. 기능을 좀 더 정확히 말하면, 순서가 있는 스트림에선 현재 스트림에서 앞단부터 시작하여 조건에 맞는 가장 긴 순열을 버리고 나머지 순열을 가져옵니다. 순서가 없는 스트림에서는 스트림 내의 요소들 중 조건에 맞는 요소들로 이루어진 부분집합을 버리고 나머지 요소들을 가져옵니다. 글로만 보면 이해하기 힘들 수 있으므로 아래 예시에서 더 자세히 살펴보도록 합시다.
// 자바 9부터 지원한다. // 이 연산은 '상태를 유지하는 중간 연산(stateful intermediate operation)'이다. takeWhile()과 마찬가지의 이유로, 병렬에다가 순서가 있는 스트림인 경우에는 비용이 많이 들 수 있으므로 주의해야 한다. default Stream<T> dropWhile(Predicate<? super T> predicate) { ... }
이해를 돕기 위해서 아래의 예시를 살펴봅시다. 아래는 순서가 있는 스트림이므로 결과로는 7, 8, 10이 출력될 것입니다.
Stream.of(2, 12, 14, 6, 7, 8, 10) // Stream<Integer> .dropWhile(i -> i % 2 == 0) .forEach(System.out::println); // 7, 8, 10이 출력된다.
그림으로 살펴보면 다음과 같습니다. 7은 조건에 맞지 않으므로 가져옵니다. 8과 10은 처음으로 조건을 만족하지 못한 7의 뒤에 있으므로 결과에 포함됩니다.

limit: 정해진 개수만큼 요소 가져오기
인수로 최대 크기를 전달합니다. 여기서 넘긴 최대 크기만큼 스트림에서 요소를 가져옵니다.
// 이 연산은 '상태를 유지하는 단락 중간 연산(short-circuiting stateful intermediate operation)'이다. 병렬에다가 순서가 있는 스트림인 경우에는 비용이 많이 들 수 있으므로 주의해야 한다. 요소를 독립적으로 처리할 수 없으며 다른 요소가 처리되었는지에 따라서 영향을 받기 때문이다. Stream<T> limit(long maxSize);
아래의 예시에서는 최대 크기가 4이므로 1, 2, 3, 4까지만 가져오고 스트림이 닫힙니다.
Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) // Stream<Integer> .limit(4) .forEach(System.out::println); // 1, 2, 3, 4가 출력된다.
skip() 연산과 섞어서 사용할 수 있습니다. 처음 3개를 스킵하고 그 뒤에 있는 4개를 가져오므로 4, 5, 6, 7이 출력될 것입니다.
Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) // Stream<Integer> .skip(3) .limit(4) .forEach(System.out::println); // 4, 5, 6, 7이 출력된다.
skip: 정해진 개수만큼 요소 스킵하기
인수로 스킵하려는 요소의 개수를 전달합니다.
// 이 연산은 '상태를 유지하는 중간 연산(stateful intermediate operation)'이다. 병렬에다가 순서가 있는 스트림인 경우에는 비용이 많이 들 수 있으므로 주의해야 한다. 요소를 독립적으로 처리할 수 없으며 다른 요소가 처리되었는지에 따라서 영향을 받기 때문이다. Stream<T> skip(long n);
아래의 예시에서는 처음 4개의 요소를 스킵하므로 나머지 5, 6, 7, 8, 9, 10이 출력됩니다. 마찬가지로 limit() 연산과 섞어서 사용할 수 있습니다.
Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) // Stream<Integer> .skip(4) .forEach(System.out::println); // 5, 6, 7, 8, 9, 10이 출력된다.
다양한 연산 활용하기 (2)
들어가기 전에
설명의 편의를 위해서 들어가기 전에 Artist, Song 클래스를 만드시고 메인 메서드가 있는 클래스에 createSample() 정적 메서드를 정의해주세요. StreamExamples 클래스를 그대로 복사하셔도 됩니다.
// Artist.java public class Artist { private String name; public Artist(String name) { this.name = name; } public String getName() { return name; } @Override public String toString() { return "Artist{" + "name='" + name + '\'' + '}'; } } // Song.java public class Song { private String title; private List<Artist> artists; private int duration; private int releaseYear; public Song(String title, List<Artist> artists, int duration, int releaseYear) { this.title = title; this.artists = artists; this.duration = duration; this.releaseYear = releaseYear; } public String getTitle() { return title; } public List<Artist> getArtists() { return artists; } public int getDuration() { return duration; } public int getReleaseYear() { return releaseYear; } @Override public String toString() { return "Song{" + "title='" + title + '\'' + ", artists=" + artists + ", duration=" + duration + ", releaseYear=" + releaseYear + '}'; } } // StreamExamples.java public class StreamExamples { public static void main(String[] args) { List<Song> songs = createSamples(); // ... } private static List<Song> createSamples() { Artist myChemicalRomance = new Artist("My Chemical Romance"); Artist sia = new Artist("Sia"); Artist billWithers = new Artist("Bill Withers"); Artist theKidLaroi = new Artist("The Kid LAROI"); Artist justinBieber = new Artist("Justin Bieber"); Artist lilMosey = new Artist("Lil Mosey"); Artist glassAnimals = new Artist("Glass Animals"); Artist jaymesYoung = new Artist("Jaymes Young"); return Arrays.asList( new Song("Famous Last Words", List.of(myChemicalRomance), 261, 2006), new Song("Welcome To The Black Parade", List.of(myChemicalRomance), 314, 2006), new Song("Breathe Me", List.of(sia), 276, 2004), new Song("Ain't No Sunshine", List.of(billWithers), 126, 2001), new Song("Stay", List.of(theKidLaroi, justinBieber), 157, 2020), new Song("Without You", List.of(theKidLaroi), 182, 2020), new Song("WRONG", List.of(theKidLaroi, lilMosey), 227, 2020), new Song("Heat Waves", List.of(glassAnimals), 235, 2020), new Song("Infinity", List.of(jaymesYoung), 237, 2017), new Song("I'll Be Good", List.of(jaymesYoung), 248, 2017) ); } }
정렬(Sorting)
sorted: 스트림 내의 요소를 정렬하기
인수를 아무 것도 넘기지 않으면 스트림이 자연스러운 순서로 정렬(예를 들면, 정수는 오름차순)되며, 정렬 기준을 따로 정하고 싶으면 Comparable 인터페이스를 구현한 객체를 인수로 넘기면 됩니다.
// 스트림 내의 요소를 서로 비교할 수 없으면(= Comparable 인터페이스를 구현하지 않았으면) ClassCastException 예외가 발생하므로 주의하자. Stream<T> sorted(); // 제공한 Comparator를 요소 간 비교에 사용한다. Stream<T> sorted(Comparator<? super T> comparator);
아래는 기본적인 정렬 예시입니다. 혹시 Comparator에 익숙하지 않으시다면 이곳으로 가서 보고 오는 것을 권장합니다.
// 인수를 넘기지 않으면 정수는 기본적으로 오름차순으로 정렬된다. List<Integer> heights = Arrays.asList(170, 172, 164, 177, 181, 187, 179); heights.stream() // Stream<Integer> .sorted() // 164, 170, 172, 177, 179, 181, 187 순으로 출력된다. .forEach(System.out::println); heights.stream() // 역순으로 정렬하고 싶으면 아래와 같이 작성할 수 있다. .sorted(Comparator.reverseOrder()) // 187, 181, 179, 177, 172, 170, 164 순으로 출력된다. .forEach(System.out::println);
이번에는 샘플 데이터를 정렬해봅시다.
List<Song> songs = createSamples(); songs.stream() // Stream<Song> // releaseYear를 키로 잡아서 정렬시킨다. .sorted(Comparator.comparingInt(Song::getReleaseYear)) .forEach(System.out::println); songs.stream() // Stream<Song> // releaseYear를 키로 잡아서 역순으로 정렬시킨다. .sorted(Comparator.comparingInt(Song::getReleaseYear) .reversed()) .forEach(System.out::println);
매핑(Mapping)
map: 현재 스트림의 각 요소에 주어진 함수를 적용한 새 스트림 반환하기
인수로 매개변수 타입이 T이고 반환 타입이 R인 람다식을 받습니다. 람다식의 인수로는 현재 스트림의 요소가 차례대로 들어가며, 함수를 거친 뒤의 반환값은 새 스트림의 요소가 됩니다. 말 그대로 스트림 내의 각 요소를 우리가 원하는 값으로 매핑합니다.
<R> Stream<R> map(Function<? super T, ? extends R> mapper);아래 예시에서는 map 연산을 통해 Stream<Song>을 Stream<String>으로 변환합니다. 여기서 매퍼 함수인 song -> song.getTitle()은 스트림 내의 Song 객체를 노래의 제목으로 매핑하는 역할을 합니다. 따라서 매핑이 모두 끝나면 map()은 Stream<String> 타입의 스트림을 반환할 것입니다.
List<Song> songs = createSamples(); songs.stream() // Stream<Song> .map(song -> song.getArtist().getName()) // Stream<String> .distinct() // Famous Last Words, Welcome To The Black Parade, Breathe Me, Ain't No Sunshine, // Stay, Without You, WRONG, Heat Waves, Infinity, I'll Be Good 순으로 출력된다. .forEach(System.out::println);
이외에도 mapToInt, mapToLong, mapToDouble과 같이 기본 특화 스트림 전용 연산들도 있습니다. 기능은 위에서 설명한 map과 동일합니다.
IntStream mapToInt(ToIntFunction<? super T> mapper); LongStream mapToLong(ToLongFunction<? super T> mapper); DoubleStream mapToDouble(ToDoubleFunction<? super T> mapper);
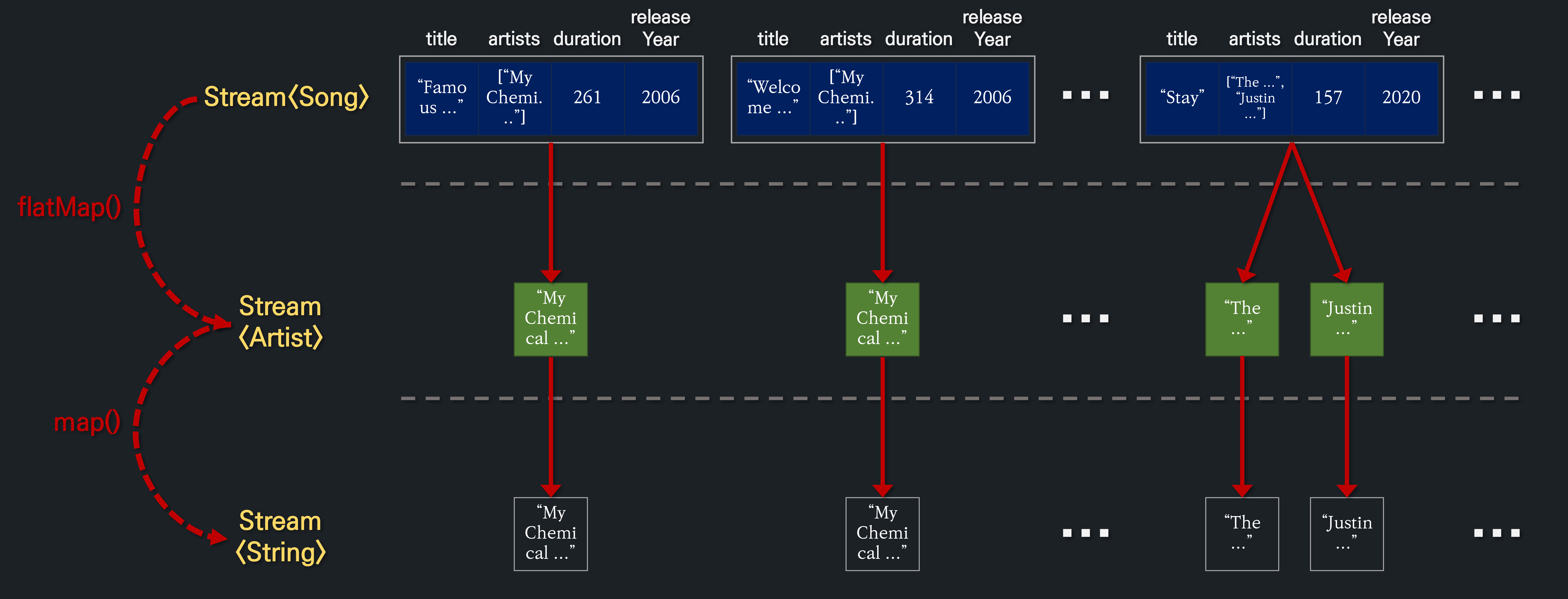
flatMap: 매핑과 평탄화(flattening)가 합쳐진 형태의 연산
인수로 매개변수 타입이 T이고 반환 타입이 Stream<R>인 람다식을 받습니다. map 연산과 기능은 비슷하지만 스트림을 반환한다는 것이 조금 특이합니다. 이 flatMap은 평탄화(flattening)와 매핑(mapping) 연산이 합쳐진 것입니다. 설명하는 것보다 직접 보시는 게 더 빠를 것 같습니다.
<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);예를 들어서, 중복 없이 모든 아티스트의 이름을 가져오고 싶다면 어떻게 구현해야 할까요? map을 통해 이를 구현하려고 하면 이름은 출력할 수 있지만 중복은 처리하기가 곤란합니다. map(Song::getArtists)의 반환형이 Stream<List<Artist>>이기 때문입니다.
songs.stream() // Stream<Song> .map(Song::getArtists) // Stream<List<Artist>> .forEach(artists -> artists.forEach( artist -> System.out.println(artist.getName())));
map 부분만 그림으로 살펴보면 다음과 같습니다. 현재 스트림 내의 각 요소(Song)를 아티스트의 이름으로 변환하려고 했으나, Song.artists가 배열이나 컬렉션 같이 반복 가능한 컨테이너(List<Artist>)이기 때문에 map으로는 어쩔 수 없이 아래와 같이 매핑할 수 밖에 없습니다.

여기서 각 리스트의 요소를 모두 꺼내서 마치 하나의 리스트로 다룰 수 있으면 distinct()로 중복 제거를 할 수 있지 않을까요? 아래와 같이 말입니다.
# 평탄화(flattening) 전 [ [Artist{name='My Chemical Romance'}], [Artist{name='My Chemical Romance'}], ..., [Artist{name='The Kid LAROI'}, Artist{name='Justin Bieber'}], ... ] # 평탄화 후 [Artist{name='My Chemical Romance'}, Artist{name='My Chemical Romance'}, ..., Artist{name='The Kid LAROI'}, Artist{name='Justin Bieber'}, ...]
바로 이때 flatMap을 사용하면 방금 말한 내용을 아래와 같이 손쉽게 구현할 수 있습니다.
List<Song> songs = createSamples(); songs.stream() // Stream<Song> .flatMap(song -> song.getArtists().stream()) // Stream<Artist> .map(Artist::getName) // Stream<String> .distinct() // My Chemical Romance, Sia, Bill Withers, The Kid LAROI // Justin Bieber, Lil Mosey, Glass Animals, Jaymes Young 순으로 출력된다. .forEach(System.out::println);
그림으로 살펴보면 대략 다음과 같습니다. 정말 간단하지 않나요?
리듀싱(Reducing)
리듀싱은 말 그대로 축소 연산을 말합니다. 축소 연산은 스트림의 요소를 합쳐서 하나의 값(또는 컬렉션)을 반환하는데, 예를 들어서 평균(average), 합계(sum), 최소(min), 최대(max), 개수(count) 등이 있습니다. 아래에 두 가지 사용법이 있는데 하나하나 차례대로 살펴보도록 합시다.
T reduce(T identity, BinaryOperator<T> accumulator); // (1) Optional<T> reduce(BinaryOperator<T> accumulator); // (2) // 이런 형태도 있지만 이는 병렬 처리에서 사용되므로 여기서는 다루지 않고 2편에서 다룬다. <U> U reduce(U identity, BiFunction<U, ? super T, U> accumulator, BinaryOperator<U> combiner);
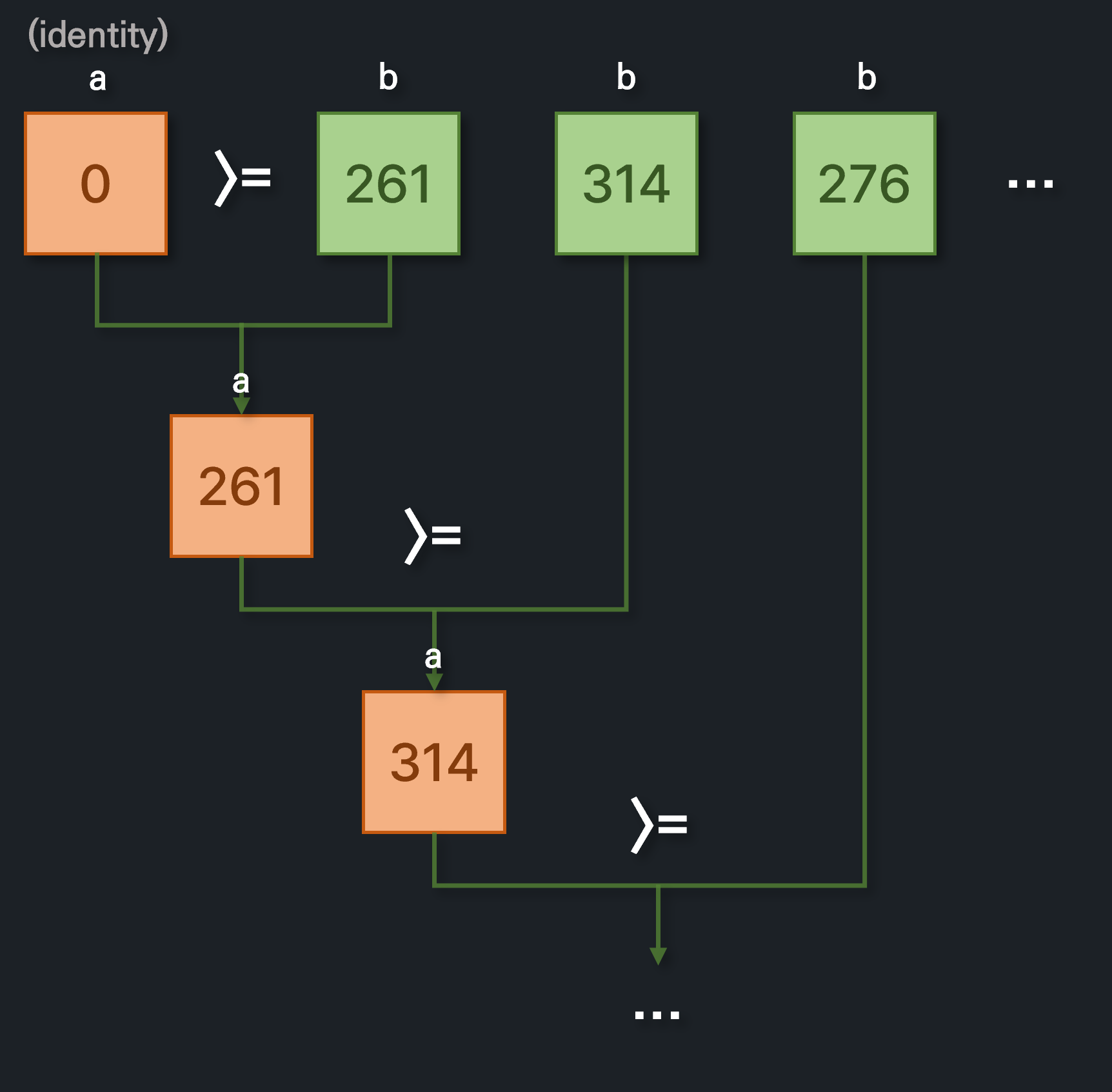
먼저 첫 번째 방법입니다. identity는 스트림에 요소가 없는 경우 초기값으로 사용되며, accumulator로 넘어가는 람다식은 2개의 파라미터를 받습니다. 첫 번째 인수로는 지금까지 누적된 값(스트림의 부분 결과)이, 두 번째 인수로는 현재 스트림의 다음 요소가 넘어옵니다.
// 메서드 선언 T reduce(T identity, BinaryOperator<T> accumulator); // 동일 코드 T result = identity; for (T element : this stream) result = accumulator.apply(result, element); return result;
음악의 재생 시간 중 가장 긴 시간(최댓값)을 뽑으려고 한다면 아래와 같이 작성할 수 있습니다.
// 물론 이 방법보다 기본 특화 스트림을 이용하는 것이 더 낫다. 이는 뒤에서 설명한다. Integer maxDuration = songs.stream() .map(Song::getDuration) // 메서드 참조로 변경하여 .reduce(0, Integer::max)로도 쓸 수 있음 .reduce(0, (a, b) -> a >= b ? a : b); System.out.println("Max duration: " + maxDuration);
이를 그림으로 간단히 살펴보면 다음과 같을 것입니다.
물론 빈 스트림이 아니므로 .reduce((a, b) -> a >= b ? a : b)처럼 초기값을 없애도 상관은 없습니다. 이게 두 번째 방법입니다. 이 경우에는 반환형이 Integer가 아니라 Optional<Integer>가 됨에 주의합시다. 만약에 빈 스트림이 넘어가면 초기값이 없으므로 결과가 null이 되기 때문에 이를 막기 위해서 Optional.empty()를 반환하는 것입니다.
// 메서드 선언 Optional<T> reduce(BinaryOperator<T> accumulator); // 동일 코드 boolean foundAny = false; T result = null; for (T element : this stream) { if (!foundAny) { foundAny = true; result = element; } else result = accumulator.apply(result, element); } return foundAny ? Optional.of(result) : Optional.empty();
기본 타입 특화 스트림
말 그대로 기본 타입에 특화된 스트림을 말합니다. 자바에서는 자주 사용하는 자료형에 맞춰서 IntStream, LongStream, DoubleStream을 지원합니다. 특화 스트림은 특화 타입과 관련된 유용한 연산들을 지원하며, 기본 타입을 다루기 때문에 자동으로 이루어지는 별도의 박싱이나 언박싱 비용이 없어서 기존 스트림을 사용하는 것보다 속도가 더 빠릅니다.
특화 스트림 생성하기
IntStream intStream = IntStream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10); DoubleStream doubleStream = DoubleStream.of(1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0); LongStream longStream = LongStream.of(1L, 2L, 3L, 4L, 5L, 6L, 7L, 8L, 9L, 10L);
위에서 볼 수 있듯이, 특화 스트림을 만드는 방법은 기존의 생성 방법과 똑같습니다. int형 특화 스트림을 예로 들면 Arrays.stream()이나 IntStream.Builder를 이용하는 방법, IntStream.generate()나 IntStream.iterate()를 이용하는 방법 등이 있습니다.
박싱된 스트림 가져오기
기본 타입이 아니라 참조 타입, 즉 객체로 다뤄야 하는 경우에는 boxed()를 사용할 수 있습니다. 예를 들어서, 컬렉션에는 기본 타입의 값을 넣을 수 없으므로 참조 타입을 사용해야 합니다.
// 메서드 선언 Stream<Integer> boxed(); // 사용 예시 List<Integer> integers = IntStream.of(1, 2, 3, 4, 5) .boxed() .collect(Collectors.toList());
반대로 박싱된 스트림에서 특화 스트림으로 변환하고 싶을 때는 어떻게 해야 할까요? 그럴 때는 mapToInt(), mapToDouble(), mapToLong()과 같이 특수한 매핑 연산을 사용하면 됩니다.
int sum = Stream.of("1", "2", "3", "4", "5") // Stream<String> .mapToInt(Integer::parseInt) // IntStream .sum(); // int System.out.println("sum = " + sum); // 15
전용 메서드 사용하기
특화 스트림에는 그 스트림에서만 사용할 수 있는 전용 메서드들이 있습니다. 공통적으로는 합계(sum), 평균(average), 최대(max), 최소(min), 개수(count)를 구하는 연산을 지원합니다.
long[] nums = { 1L, 2L, 3L, 4L, 5L }; // 스트림은 재사용할 수 없으니 사용이 끝나면 새로운 스트림을 만들어야 한다. // 스트림을 재사용하는 경우 IllegalStateException 예외가 발생하니 주의하자. long sum = Arrays.stream(nums).sum(); double average = Arrays.stream(nums).average().getAsDouble(); long max = Arrays.stream(nums).max().getAsLong(); long min = Arrays.stream(nums).min().getAsLong(); long count = Arrays.stream(nums).count(); System.out.println("sum = " + sum); // 15 System.out.println("average = " + average); // 3.0 System.out.println("max = " + max); // 5 System.out.println("min = " + min); // 1 System.out.println("count = " + count); // 5
여기서 평균, 최대, 최소를 구하는 연산 시 반환 타입이 Optional인데 이는 빈 스트림인 경우 평균, 최대, 최소를 구할 수 없기 때문입니다. 합계, 개수는 아무것도 없으면 0을 반환하면 되기 때문에 Optional이 필요가 없습니다. 만약에 스트림을 일일이 생성하지 않고 한꺼번에 구하고 싶은 경우에는 SummaryStatistics를 사용할 수 있습니다.
LongSummaryStatistics stats = Arrays.stream(nums).summaryStatistics(); // 만약 빈 스트림이면 평균은 기본값으로 0.0d, 최대는 Long.MIN_VALUE, 최소는 Long.MAX_VALUE를 반환하니 주의하자. System.out.println("stats.getAverage() = " + stats.getAverage()); System.out.println("stats.getCount() = " + stats.getCount()); System.out.println("stats.getMax() = " + stats.getMax()); System.out.println("stats.getMin() = " + stats.getMin()); System.out.println("stats.getSum() = " + stats.getSum());
참고
'프로그래밍 관련 > 자바' 카테고리의 다른 글
| 33편. 파일 입출력(File input and output) (40) | 2022.05.04 |
|---|---|
| 27편. 컬렉션(Collections) (1) | 2022.04.26 |
| 32편. 람다식(Lambda expression) (1) | 2022.02.22 |
| 34편. 애노테이션(Annotation) (0) | 2022.02.18 |
| 26편. 제네릭(Generic) (0) | 2022.02.06 |
댓글을 사용할 수 없습니다.