33편. 파일 입출력(File input and output)

스트림(Stream)
파일 입출력을 알아보기 전에 스트림이 무엇인지 이해해야 합니다. 여기서 말하는 스트림은 읽거나 쓸 수 있는 1차원적인 데이터의 흐름을 말합니다. 마치 강이 상류에서 하류로 흐르는 것처럼, 데이터도 어느 한 출발지(source)에서 목적지(destination)로 흐르는 것처럼 말이죠. 여기서 출발지와 목적지는 파일, 키보드나 모니터, 원격 네트워크, 데이터베이스 시스템, 다른 프로그램 등과 같이 다양한 자원들이 될 수 있습니다.

프로그램을 기준으로 잡고 외부 자원(파일, 키보드 등)으로부터 데이터를 읽고 싶다고 해봅시다. 그러면 자연스럽게 외부 자원은 데이터의 출발지 혹은 데이터의 원천이 될 것입니다. 이렇게 출발지에서 생성된 데이터는 목적지인 프로그램으로 흐릅니다. 이때 이 흐름을 입력 스트림이라고 하며 이를 통해서 외부 자원으로부터 데이터를 읽어올 수 있습니다.
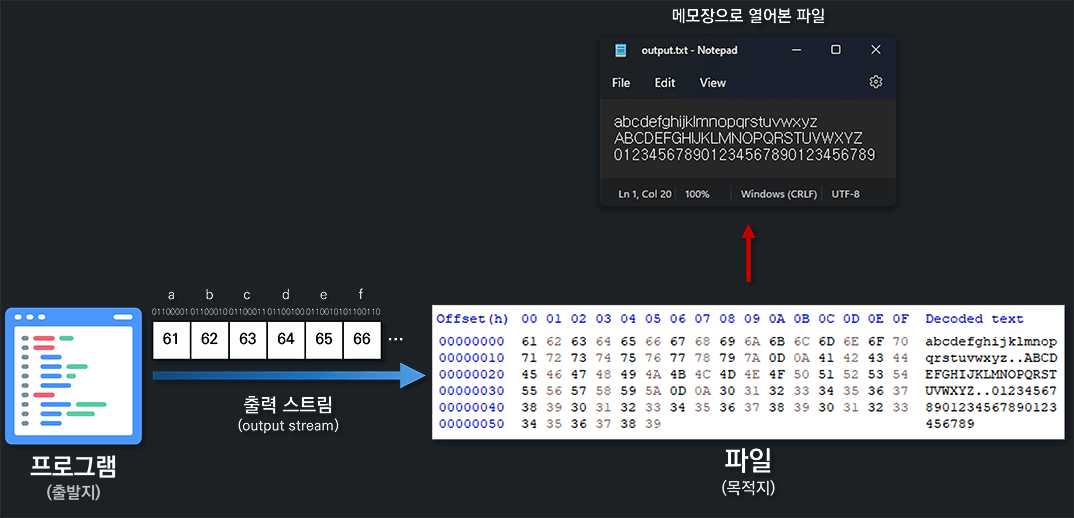
반대로 프로그램에서 외부 자원에 데이터를 쓰고 싶다고 해봅시다. 그러면 이제는 프로그램이 데이터의 출발지가 됩니다. 이렇게 출발지에서 생성된 데이터는 목적지인 외부 자원으로 흐릅니다. 이때 이 흐름을 출력 스트림이라고 하며 이를 통해서 외부 자원에 데이터를 쓸 수 있습니다. 이처럼 자바는 스트림을 통해서 프로그램에서 일어나는 입출력을 처리하며, 이 스트림은 흐름의 방향에 따라서 입력 스트림과 출력 스트림으로 나뉘는 것을 볼 수 있습니다.
파일 입출력(File Input and Output)
또한 스트림은 데이터의 형태(바이트 스트림, 문자 스트림)에 따라서 다시 나뉠 수 있습니다. 우선 바이트 스트림부터 살펴보도록 하겠습니다.
바이트 스트림(Byte Streams)
프로그램은 바이트 스트림을 사용해서 8개의 비트로 이루어진 바이트를 외부 자원에 쓰거나 읽어들일 수 있습니다. 자바의 모든 바이트 스트림 클래스는 InputStream과 OutputStream을 상속하고 있습니다. 여기서는 파일 입출력 바이트 스트림인 FileInputStream, FileOutputStream을 한번 살펴보도록 하겠습니다.
FileInputStream
우선은 C:\tutorial 경로에 예제에 사용할 input.txt 파일을 생성해주세요. 여기서 input.txt의 내용은 아래와 같이 작성해주세요.
abc
123그 후 아래의 예시를 한번 실행해봅시다. 방금 텍스트 파일에 적었던 문자열이 결과창에 그대로 출력될 것입니다.
public class JavaTutorial33 {
// 파일을 찾을 수 없거나 입출력 에러가 발생하면 FileNotFoundException이나 IOException의 예외가 발생한다. 이것들은 검사 예외(checked exception)기 때문에 개발자가 catch로 잡아서 처리해야 하지만 이 예시에서는 예외를 잡아도 할 수 있는게 없으므로 throws로 다시 던진다.
public static void main(String[] args) throws IOException {
FileInputStream in = null;
try {
// 지정 경로에 파일이 없다면 FileNotFoundException이 발생한다. 따라서 C:\tutorial(아니면 원하는 다른 경로에)에 input.txt가 있는지 확인하자.
in = new FileInputStream("C:\\tutorial\\input.txt");
int ch;
while ((ch = in.read()) != -1) {
System.out.print((char) ch);
}
} finally {
// 스트림이 더 이상 필요하지 않으면 닫아줘야 한다.
// 이것에 관해서는 '스트림 닫기'에서 설명한다.
if (in != null) {
in.close();
}
}
}
}여기서 차례대로 살펴봅시다. 우선 아래를 보면 우리가 지정한 경로에 있는 실제 파일을 열어서 파일에서 프로그램으로 흐르는 입력 스트림을 만듭니다. 이때, 지정 경로에 파일이 존재하지 않거나, 파일이 아니라 디렉터리이거나, 다른 이유로 파일을 읽을 수 없는 경우에는 FileNotFoundException 예외가 발생합니다.
// 파일에 대한 읽기 권한이 없는 경우에는 SecurityException이 발생한다.
in = new FileInputStream("C:\\tutorial\\input.txt");우리가 이렇게 입력 스트림을 만든 후 이를 통해서 파일에서 읽어올 일만 남았습니다. 그게 바로 아래 부분입니다. 우리가 read()를 호출하면 입력 스트림에서 1바이트의 데이터를 읽습니다. 만약에 데이터를 읽다가 파일의 끝에 도달하여 더이상 읽을 데이터가 없는 경우에는 -1을 반환합니다. 따라서 아래의 코드는 파일의 끝까지 데이터를 읽어서 이를 출력하게 됩니다.
int ch;
while ((ch = in.read()) != -1) {
System.out.print((char) ch);
}
// 위 코드가 잘 이해가 안가는 사람은 아래처럼 분리해서 바라보자.
int ch = in.read();
while (ch != -1) {
System.out.print((char) ch);
ch = in.read();
}아래를 보면 바이트가 차례대로 넘어오는 것을 볼 수 있습니다. 번호 97(01100001)은 영문자 a, 49(00110001)는 숫자 1에 대응시킨 것으로 여기서 번호 97과 49를 아스키 코드라고 부릅니다. 인터넷에 '아스키 코드표' 혹은 'ascii table'이라고 검색하면 다른 문자는 어느 번호에 대응되는지 한눈에 확인해볼 수 있습니다(1바이트로는 256개의 문자만 처리할 수 있으므로 무수히 많은 문자를 지닌 한글이나 일본어, 중국어 등은 온전히 표현할 수 없습니다. 이와 관련해서는 뒤에서 천천히 살펴볼 것입니다).
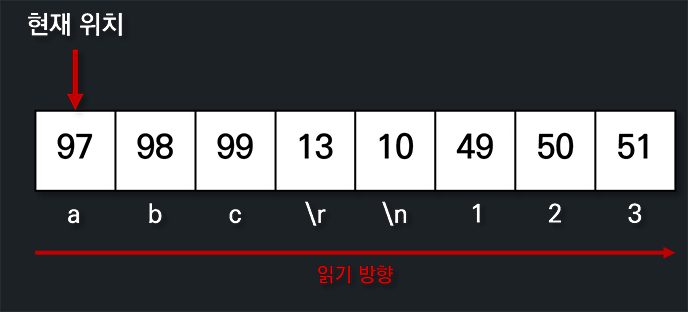
여기서 하나 신경쓰이는 것이 있는데 개행이 \n가 아니라 \r\n이라는 것입니다. 보통 다른 운영체제(맥, 리눅스 등)에서는 \n을 개행으로 사용하지만, 윈도우에서는 \r\n이 개행으로 자주 사용됩니다. 그러니 이를 하나로 묶어서 개행 문자로 바라봅시다.
FileOutputStream
이번에는 새로운 파일을 한번 써보도록 하겠습니다. 기본적인 틀은 비슷하고 그저 FileInputStream이 FileOutputStream으로 바뀌었으며, 바이트를 읽는 read() 대신에 바이트를 쓰는 write() 메서드를 호출한다는 차이가 있습니다.
public class JavaTutorial33 {
public static void main(String[] args) throws IOException {
FileOutputStream out = null;
String content = "abc\n123"; // 파일에 쓸 내용
try {
// 마찬가지로 해당 경로에 파일은 존재하지만 그 파일이 일반 파일이 아니라 디렉터리인 경우, 존재하지 않지만 파일을 새로 만들 수 없는 경우, 다른 이유로 파일을 열 수 없는 경우에는 FileNotFoundException 예외가 발생한다.
out = new FileOutputStream("C:\\tutorial\\output.txt");
out.write(content.getBytes());
} finally {
if (out != null) {
out.close();
}
}
}
}여기서 String.getBytes() 메서드는 문자열을 바이트 배열로 돌려주는 기능을 합니다. 따라서 write() 메서드를 통해 바이트 배열을 파일의 출력 스트림에 쓰는 것입니다.
out.write(content.getBytes()); 위의 예제를 실행시켜보면 C:\tutorial 경로에 output.txt 파일이 생성된 것을 확인해볼 수 있습니다. 파일을 열고 내용이 올바르게 써졌는지 확인해봅시다. 이상이 없다면 이번에는 8행의 코드를 아래와 같이 변경해봅시다.
// 기존의 파일이 없으면 새 파일을 생성한다.
out = new FileOutputStream("C:\\tutorial\\output.txt", true);두 번째 인수(append)는 기본적으로 false지만 true를 넘기면 파일을 새로 작성하지 않고 기존의 내용에 덧붙일 수 있습니다. 이렇게 변경한 뒤 예제를 실행해보면 C:\tutorial\output.txt의 내용이 다음과 같이 바뀌어 있을 것입니다.
abc
123abc
123문자 스트림(Character Streams)
모든 문자 스트림 클래스는 Reader 혹은 Writer의 하위 클래스입니다. 즉, 직접적으로든 간접적으로든 이 두 클래스 중 하나를 상속하고 있습니다. 보통 바이트 단위로 세밀한 조작이 필요할 때는 바이트 스트림을 사용하지만, 문자를 다룰 때는 문자 스트림을 사용합니다. 웬만해서는 파일에 바이트를 직접 읽고 쓸 일이 없으므로 문자 스트림을 자주 사용하게 될 것입니다.
FileReader
아래 예제는 FileInputStream을 다룰 때 살펴봤던 예제에서 FileInputStream을 그저 FileReader로 바꾼 것 뿐입니다. 그래도 별다른 에러 없이 동일하게 동작합니다.
public class JavaTutorial33 {
public static void main(String[] args) throws IOException {
FileReader in = null;
try {
in = new FileReader("C:\\tutorial\\input.txt");
int ch;
while ((ch = in.read()) != -1) {
System.out.print((char) ch);
}
} finally {
if (in != null) {
in.close();
}
}
}
}그러면 FileReader와 FileInputStream은 뭐가 다른 것일까요? FileInputStream의 read() 메서드는 1바이트만 읽었던 것과 다르게, FileReader의 read() 메서드는 1개의 문자를 읽습니다. 무슨 차이가 있을까요?
while ((ch = in.read()) != -1) { ... }C:\tutorial\input.txt 파일을 열어서 내용을 아래와 같이 수정해봅시다. 그런 다음에 한번은 FileInputStream을 이용해 출력해보고, 또 한번은 FileReader를 사용해 출력해봅시다.
가나다
abc
123그러면 아래와 같은 출력 결과를 살펴볼 수 있습니다. 차이를 눈치채셨나요? FileReader를 사용하면 한글이 정상적으로 출력되지만, FileInputStream을 사용하면 한글이 깨지는 것을 볼 수 있습니다. 위에서도 말했듯이 한글은 문자(11,172자)가 많아서 1바이트가 아니라 2바이트(16비트, 즉 \(2^{16}=65,536\)개의 문자를 표현할 수 있다)로 처리해야 합니다.

이렇게 문자가 프로그램으로 넘어오는 것을 확인할 수 있습니다. 여기서 한글과 대응되는 숫자는 인터넷에 '유니코드표' 혹은 'unicode table'이라고 검색하면 확인할 수 있습니다. 참고로, 유니코드는 전 세계에 있는 모든 문자를 어느 컴퓨터에서나 동일하게 표현할 수 있도록 설계된 국제 표준을 말합니다.

FileWriter
아래 예제는 FileOutputStream을 다룰 때 살펴봤던 예제와 별반 차이가 없어 보입니다. FileWriter의 write() 메서드로는 한 바이트가 아니라 하나의 문자 혹은 문자열을 쓸 수 있습니다.
public class JavaTutorial33 {
public static void main(String[] args) throws IOException {
FileWriter out = null;
String content = "가나다\nabc\n123"; // 파일에 쓸 내용
try {
out = new FileWriter("C:\\tutorial\\output.txt");
// 이제는 바이트 배열이 아니라 문자 혹은 문자열을 넘길 수 있다.
out.write(content);
} finally {
if (out != null) {
out.close();
}
}
}
}예제를 실행하고 C:\tutorial\output.txt 파일의 내용을 확인하면 제대로 수정된 것을 확인할 수 있습니다. 이번에는 7행에 있는 코드에서 인수에 true를 추가해보도록 하겠습니다. 두 번째로 넘어가는 인수(append)는 기본적으로 false이지만 true로 변경하면 파일을 새로 쓰는 게 아니라 기존의 내용에 덧붙일 수 있습니다.
// 기존의 파일이 없으면 새 파일을 생성한다.
out = new FileWriter("C:\\tutorial\\output.txt", true);그런 뒤에 예제를 실행시켜보면 아래와 같이 기존의 내용에 덧붙여진 것을 확인할 수 있습니다.
가나다
abc
123가나다
abc
123버퍼 스트림(Buffered Streams)
앞에서 봤던 스트림은 모두 버퍼링되지 않는, 즉 버퍼를 사용하지 않는 스트림(unbuffered stream)이었습니다. 여기에서는 버퍼를 사용하는 스트림들을 살펴보겠습니다. 그럼 버퍼(buffer)는 대체 무엇일까요?
버퍼(Buffer)
보통 버퍼는 데이터를 한 곳에서 다른 곳으로 보낼 때 데이터가 임시로 저장되는 공간을 말합니다. 먼저 버퍼를 사용하는 BufferedInputStream의 내부를 살펴보면 생성 시 기본 크기(8KB, 즉 8192)의 바이트 배열 buf가 만들어지는 것을 확인할 수 있습니다.
public class BufferedInputStream extends FilterInputStream {
// 기본 버퍼의 크기는 8KB(8192 바이트)이다.
private static int DEFAULT_BUFFER_SIZE = 8192;
// 데이터가 저장되는 내부 버퍼 배열이다.
protected volatile byte buf[];
...
}그러면 여기서 버퍼는 왜 필요한 걸까요? 우리가 파일을 읽거나 쓰려고 할 때마다 내부에서는 읽거나 쓰는 등의 파일 조작을 위해 시스템 콜이 일어납니다. 이는 무거운 작업이기 때문에 최소한의 호출 횟수로 우리가 원하는 내용을 모두 가져올 수 있으면 좋을 것입니다. 따라서 한 번에 하나의 바이트를 읽는 것을 반복하는 것보다는, 버퍼의 크기만큼 여러 바이트를 한꺼번에 요청해서 받은 결과를 버퍼에 임시로 저장해두는 것이 좋습니다. 이러면 버퍼를 다 읽기 전까지는 별도의 요청을 하지 않아도 된다는 장점이 있습니다.
헷갈릴 때는 버퍼 스트림을 사용하자
파일 입출력에만 적용되는 얘기는 아니고 스트림을 통해 읽거나 쓸 때마다 시스템 콜, 네트워크 활동 등과 같이 상대적으로 비용이 많이 드는 작업을 해야 하는 경우에는 일반적으로 버퍼 스트림을 사용하는 것이 더 낫습니다. 버퍼 스트림은 보통 한 번에 1바이트나 몇 바이트를 조금씩 읽으면서 처리하는 작업을 많이 수행해야 하는 경우에 적합합니다. 한 번에 대량의 바이트를 받아서 처리하려는 경우 버퍼 스트림이 도움이 되지 않을 수 있으니 참고하세요. 혹은 readLine() 등과 같이 버퍼 스트림에서 지원되는 메서드를 사용하려고 하는 경우 유용합니다. 헷갈리면 버퍼 스트림을 우선 채택하고 고민해보는 것도 나쁘지는 않습니다.
public class BufferedInputStream extends FilterInputStream {
public synchronized int read() throws IOException {
// 버퍼가 비어 있거나 다 읽은 상태면
// 외부 자원으로부터 새로운 데이터를 다시 가져와서 버퍼를 채운다.
if (pos >= count) {
fill();
// 버퍼를 채웠는데도 더 이상 읽을게 없으면 끝에 도달했다고 판단한다.
if (pos >= count)
return -1;
}
// 입력 스트림이 아니라 버퍼(buf)에서 읽을 바이트를 가져온다.
return getBufIfOpen()[pos++] & 0xff;
}
...
}예를 들어서 파일의 길이가 16KB(16,384 바이트)라고 해봅시다. 그러면 이 파일을 FileInputStream.read()를 호출하여 1바이트씩 모두 읽으려고 한다면 16384번의 디스크 접근이 일어납니다. 하지만 BufferedInputStream.read()를 사용하면 버퍼의 크기만큼 한꺼번에 읽을 수 있으므로 디스크에 2번(8192 * 2)만 접근하면 파일의 내용을 모두 읽을 수 있게 됩니다.
BufferedInputStream과 BufferedOutputStream
FileInputStream을 살펴볼 때 봤던 예제에 BufferedInputStream을 넣어봅시다. 아래 예제를 살펴보면 그렇게 변한 부분은 없습니다.
public class JavaTutorial33 {
public static void main(String[] args) throws IOException {
BufferedInputStream in = null;
try {
// BufferedInputStream은 입력 스트림(InputStream)을 감싸는 래퍼 클래스다.
in = new BufferedInputStream(new FileInputStream("C:\\tutorial\\input.txt"));
int ch;
while ((ch = in.read()) != -1) {
System.out.print((char) ch);
}
} finally {
// BufferedInputStream을 닫으면 안에서 사용하는 InputStream(여기서는 FileInputStream)도 같이 닫는다.
if (in != null) {
in.close();
}
}
}
}BufferedOutputStream도 마찬가지로 내부에 기본 크기가 8KB인 버퍼 배열을 가지고 있으며, write() 메서드를 호출하여 내용을 기록할 때 파일에 직접 쓰지 않고 버퍼에 우선 씁니다. 그러면 이렇게 버퍼에 쓴 내용을 파일에도 반영해야 하는데 이를 위해선 개발자가 flush() 메서드를 호출해야 합니다.
public class JavaTutorial33 {
public static void main(String[] args) throws IOException {
BufferedOutputStream out = null;
String content = "abc\n123"; // 파일에 쓸 내용
try {
// BufferedOutputStream은 출력 스트림(OutputStream)을 감싸는 래퍼 클래스다.
out = new BufferedOutputStream(new FileOutputStream("C:\\tutorial\\output.txt"));
out.write(content.getBytes());
} finally {
if (out != null) {
out.close();
}
}
}
}위 예제에는 flush() 메서드가 보이지 않지만 스트림을 닫는 close() 메서드를 살펴보면 아래와 같이 내부에서 flush() 메서드를 호출하는 것을 볼 수 있습니다.
public void close() throws IOException {
try (OutputStream ostream = out) {
flush();
}
}BufferedReader와 BufferedWriter
BufferedReader와 BufferedWriter도 사용법이 비슷합니다. BufferedWriter도 아래와 같이 FileWriter를 감싸서 사용하면 됩니다.
public class JavaTutorial33 {
public static void main(String[] args) throws IOException {
BufferedReader in = null;
try {
in = new BufferedReader(new FileReader("C:\\tutorial\\input.txt"));
int ch;
while ((ch = in.read()) != -1) {
System.out.print((char) ch);
}
} finally {
if (in != null) {
in.close();
}
}
}
}여기서 BufferedReader에 readLine()이라는 메서드가 추가되었는데, 이름을 보면 알 수 있듯이 파일의 줄을 읽어서 반환합니다. 즉 현재 위치에서 개행 문자(\n, \r, \r\n)를 만날 때까지 문자열을 읽는 것입니다. 반환값에는 개행 문자가 포함되지 않는다는 점을 기억해주세요.
String line;
// readLine()은 더 이상 읽을 내용이 없으면 null을 반환한다.
while ((line = in.readLine()) != null) {
System.out.println(line);
}BufferedWriter에는 newLine()이라는 메서드가 추가되었는데 말 그대로 현재 위치에 개행 문자를 삽입하는 기능입니다. 아래의 예제를 실행 후 파일을 확인해보면 이해할 수 있습니다.
public class JavaTutorial33 {
public static void main(String[] args) throws IOException {
BufferedWriter out = null;
try {
out = new BufferedWriter(new FileWriter("C:\\tutorial\\output.txt"));
out.write("가나다");
out.newLine();
out.write("abc");
out.newLine();
out.write("123");
} finally {
if (out != null) {
out.close();
}
}
}
}차이 비교
아래의 예제를 실행해보고 소요 시간을 확인 후, 7행의 주석을 해제한 뒤 8행을 주석 처리한 후에 예제를 다시 한번 실행해봅시다. 소요 시간은 부정확하므로 대충 얼마나 빠른지 느린지만 확인해주세요. 아마 상당한 차이를 볼 수 있을 것입니다.
public class JavaTutorial33 {
public static void main(String[] args) throws IOException {
String filePath = "C:\\tutorial\\test.txt";
createSampleFile(filePath);
long startTime = System.nanoTime();
// readFileUsingBufferedStream(filePath);
readFileUsingUnbufferedStream(filePath);
long endTime = System.nanoTime();
System.out.println("소요된 시간: " + (endTime - startTime) / 1_000_000 + " ms");
removeFile(filePath);
}
// 버퍼를 사용하지 않는 스트림을 통해 파일 읽기
private static String readFileUsingUnbufferedStream(String path) throws IOException {
StringBuilder builder = new StringBuilder();
FileInputStream in = null;
try {
in = new FileInputStream(path);
int ch;
while ((ch = in.read()) != -1) {
builder.append((char) ch);
}
} finally {
if (in != null) {
in.close();
}
}
return builder.toString();
}
// 버퍼를 사용하는 스트림을 통해 파일 읽기
private static String readFileUsingBufferedStream(String path) throws IOException {
StringBuilder builder = new StringBuilder();
BufferedInputStream in = null;
try {
in = new BufferedInputStream(new FileInputStream(path));
int ch;
while ((ch = in.read()) != -1) {
builder.append((char) ch);
}
} finally {
if (in != null) {
in.close();
}
}
return builder.toString();
}
// 영문자로 이루어진 1 MB 크기의 무작위 샘플 파일 만들기
private static void createSampleFile(String path) throws IOException {
Random random = new Random();
BufferedOutputStream out = null;
int fileSize = 1024 * 1024; // 1 MB
try {
out = new BufferedOutputStream(new FileOutputStream(path));
for (int i = 0; i < fileSize; i++) {
out.write(random.nextInt('z' - 'a') + 'a');
}
} finally {
if (out != null) {
out.close();
}
}
}
// 생성한 파일은 필요가 없으므로 삭제할 용도로 정의한 메서드
private static void removeFile(String path) throws IOException {
java.nio.file.Path filePath = java.nio.file.Paths.get(path);
Files.deleteIfExists(filePath);
}
}스트림 닫기
우리가 마치 다 읽거나 쓴 파일이나 프로그램 등을 닫는 것과 마찬가지로, 스트림을 더 이상 사용할 일이 없으면 반드시 닫아줘야 합니다. 사용하지도 않는데 스트림을 열어둔 채로 있으면 시스템 자원을 낭비하기 때문입니다. 실수로 닫지 않으면 그게 곧 잠재적인 메모리 누수(memory leak)로 이어질 수 있습니다.
기초적인 방법
가장 단순한 방법입니다. 문제가 없어 보일 수도 있지만 중간에 예외가 발생하면 in.close()가 실행되지 않는다는 치명적인 문제가 있습니다. 거기에다가 사용을 모두 마치고 나서 close()를 호출해야 한다는 사실을 쉽게 잊어버릴 수도 있습니다.
FileInputStream in = new FileInputStream("C:\\tutorial\\input.txt");
int ch;
while ((ch = in.read()) != -1) {
System.out.print((char) ch);
}
in.close();관용적인 방법
보통은 나중에 찾아볼 수 있도록 예외를 로그에 기록하거나 예외를 잡아서 다시 던지지만, 잡아도 지금 단계에서는 어찌 해볼 수 없다면 굳이 잡지는 않습니다. 하지만 예외가 발생해서 스트림을 닫는 코드가 실행되지 않을 수 있으므로 아래의 코드를 관용적으로 사용해왔습니다. finally 블록은 예외가 발생하더라도 반드시 실행되므로 스트림을 닫기에 가장 좋은 장소입니다.
FileInputStream in = null;
FileOutputStream out = null;
try {
in = new FileInputStream("C:\\tutorial\\input.txt");
out = new FileOutputStream("C:\\tutorial\\output.txt");
// ...
} finally {
if (in != null) {
in.close();
}
if (out != null) {
out.close();
}
}그러나 이러한 방법은 여전히 메모리 누수에 안전하지 않습니다. 예를 들어서 try 블록에서 예외가 발생한 뒤에 finally 블록에서 스트림을 닫으려고 했으나 in.close()에서 IOException이 발생한다면 어떻게 될까요? 이러면 out.close()이 실행되지 않을 것입니다. 거기에다가 try 블록에서 발생했던 예외는 finally 블록에서 발생한 IOException에 묻혀서 근본 원인을 찾을 수 없게 되는 문제점도 있습니다. 이를 아래와 같이 처리할 수도 있지만 매우 난잡합니다. 별도로 close(Closeable) 메서드를 만들어서 처리할 수도 있겠지만 자바 7 이후로는 이것보다 더 나은 방법(try-with-resources)이 있습니다.
try {
// ...
} finally {
if (in != null) {
try {
in.close();
} catch (IOException ignored) {
// 필요에 따라서 무시하거나 로그를 기록함
}
}
if (out != null) {
try {
out.close();
} catch (IOException ignored) {
// ...
}
}
}try-with-resources
기본 사용법
try-with-resources문을 사용하면 하나 이상의 자원(resource, 보통 리소스라고도 많이 부름)를 간편하게 닫을 수 있습니다. 여기서 자원은 사용이 끝난 후 닫아야 하는 객체를 말합니다. try 키워드 바로 뒤에 등장하는 괄호 안에다 선언합니다. 이게 사실상 핵심이며, 위에서 설명한 방법은 잊어도 좋습니다. 자원을 회수해야 하는 경우에는 반드시 try-with-resources를 사용합시다.
try (FileInputStream in = new FileInputStream("C:\\tutorial\\file.txt")) {
...
}물론 괄호 안에 아무 타입의 변수나 선언할 수 있는 건 아닙니다. AutoCloseable 인터페이스를 구현한 클래스 타입의 참조형 변수만 올 수 있습니다. Closeable 인터페이스는 AutoCloseable 인터페이스를 상속하므로 대신 Closeable을 구현해도 됩니다.
// 이 인터페이스를 구현한 클래스의 인스턴스는 try-with-resources 블록을
// 나갈 때 close()가 자동으로 호출된다.
public interface AutoCloseable {
void close() throws Exception;
}
public interface Closeable extends AutoCloseable {
public void close() throws IOException;
}버퍼 스트림에서 살펴봤던 예제 코드를 try-with-resources문을 사용해 바꿔보도록 하겠습니다. 그러면 아래와 같이 상당히 간결해진 코드를 만나볼 수 있습니다. 여기서 catch문이나 finally문이 필요하다면 try-catch-finally 처럼 쓰던 대로 쓰면 됩니다.
try (BufferedInputStream in = new BufferedInputStream(new FileInputStream("C:\\tutorial\\input.txt"))) {
int ch;
while ((ch = in.read()) != -1) {
System.out.print((char) ch);
}
}내부 동작
컴파일 후 생성된 클래스 파일을 뜯어보면 아래와 같은 구조가 나옵니다. 향후 변경될 수 있으니 대충 흐름만 살펴봅시다. 중요한 부분은 아니므로 가볍게 보고 넘어가도 좋습니다.
BufferedInputStream in = new BufferedInputStream(new FileInputStream("C:\\tutorial\\input.txt"));
// 예외 계층을 떠올려보자. 모든 예외 클래스가
// Throwable을 간접적으로든 직접적으로든 상속하고 있다.
Throwable var2 = null;
try {
int ch;
try {
while((ch = in.read()) != -1) {
System.out.print((char)ch);
}
} catch (Throwable var11) {
// 예외가 발생하면 잡아서 임시 변수에 담아두고 예외를 다시 던진다.
var2 = var11;
throw var11;
}
} finally {
if (in != null) {
// 위의 try 블록에서 예외가 발생했는데 finally 블록에서도 예외가
// 발생하면 기존의 예외가 버려지므로 예외 발생 여부를 체크해야 한다.
if (var2 != null) {
try {
in.close();
} catch (Throwable var10) {
// 자원을 닫을 때 예외가 발생하면 이 예외도 확인해볼 수 있도록
// 기존 예외 객체에 숨겨진 예외를 추가한다. 이 예외는 나중에
// Throwable에 있는 getSuppressed() 메서드로 확인해볼
// 수 있다.
var2.addSuppressed(var10);
}
} else {
// 위에서 예외가 발생한게 없으면 아래의 문장에서 예외가 발생해도
// 문제될 것이 없다. 그 예외가 최초 예외이기 때문에 버려지는 예외
// 가 없기 때문이다.
in.close();
}
}
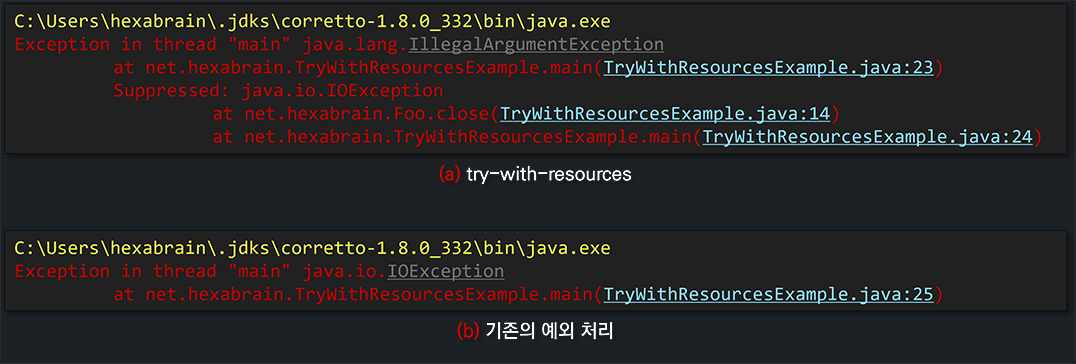
}try-with-resources문 내부에서 호출되는 addSuppressed() 메서드로 추가된 숨겨진 예외는 아래와 같이 출력됩니다. 마지막으로 발생한 예외 이전에 발생했던 예외들을 함께 볼 수 있다는 점을 기억해둡시다.
여러 개의 변수 선언
try 블록 내에 한개만 선언할 수 있는 건 아닙니다. 필요하면 여러 개를 선언할 수도 있습니다.
try (FileReader in = new FileReader("C:\\tutorial\\output.txt");
BufferedReader reader = new BufferedReader(in)) {
// ...
}자바 8 이전에는 자원을 괄호 안에서 모두 선언해야 하므로 코드를 아래와 같이 작성할 수 없습니다. 하지만 자바 9 이후부터는 개선이 되어서 괄호 외부에 선언할 수 있게 되었습니다.
BufferedReader reader = new BufferedReader(new FileReader("C:\\tutorial\\output.txt"));
// 두 개 이상인 경우에는 try(in; reader)와 같이 세미콜론으로 구분해주면 된다.
try (reader) {
// ...
}그러면 닫히는 순서는 어떻게 될까요? 자원(resource)은 초기화 순서의 역순으로 닫힙니다. 따라서 아래의 예시에서는 먼저 bar.close()가 호출되고 그 다음에 foo.close()가 호출됩니다.
try (Foo foo = new Foo();
Bar bar = new Bar()) {
// ...
}여기서 더 궁금한 점이 있다면 아래의 예시를 조금씩 변형시켜 보면서 해소해보세요. 아니면 댓글로 남겨주셔도 괜찮습니다.
public class JavaTutorial33 {
public static void main(String[] args) throws IOException {
Foo foo = new Foo();
Bar bar = new Bar();
System.out.println("try 블록 전");
try (foo; bar) {
System.out.println("try 블록 내부");
}
System.out.println("try 블록 후");
}
static class Foo implements Closeable {
@Override
public void close() throws IOException {
System.out.println("Foo.close");
}
}
static class Bar implements Closeable {
@Override
public void close() throws IOException {
System.out.println("Bar.close");
}
}
}'프로그래밍 관련 > 자바' 카테고리의 다른 글
| 번외편. 인터페이스라는 이름의 계약 (0) | 2022.05.14 |
|---|---|
| 37편. 열거형(Enum Types) (0) | 2022.05.05 |
| 27편. 컬렉션(Collections) (1) | 2022.04.26 |
| 35편. 스트림(Streams) (1) (0) | 2022.04.04 |
| 32편. 람다식(Lambda expression) (1) | 2022.02.22 |